目录
COMP6991 - Solving Modern Programming Problems with Rust
Final Exam for 22T3
With my own solution (might be incorrect)
Question 1
1.1
Question
- Explain the difference between the Option and Result types. (1 mark)
- Give an example of where each might be used. (2 marks)
Explain the difference between the Option and Result types.
Option<T> is used to set a variable's value. The value could exist or not. It could avoid some empty pointer error.
Some(T): variable has value, type is T.None: variable does not have value.
Result<T, E> is used to handle error processing. An operation result could be successful or fail. Result could handle these two result.
Ok(T): operation success. The result is T.Err(E): operation failed. The result is E (usually be the error message).
Give an example of where each might be used.
If a function wants to find an variable's value index in an array, but the array may not have any elements whose value is equal to the variable, this situation can use Option<i32> as the return variable. If function find that index, it could return Some(index), or return None.
If a function wants to find a word from a centence in a text file, but the file may not have any words like it, this situation can use Result<String, String>. If function finds the word, it could return Ok(content) to return that snetence, or return Err(format!("This file does not include any word: {}", word)).
1.2
Question
The following Rust code fails to compile, but equivalent code in other popular programming languages (e.g. C, Java, Python) compiles and/or works correctly.
RUSTlet i: u32 = 32;
let j: i32 = -1;
println!("{}", i + j);
Question:
- Explain what issue(s) prevent the Rust compiler from building this code (1 mark).
- Explain the philosophy behind this language decision (1 mark).
Explain what issue(s) prevent the Rust compiler from building this code
These two integer variables have different types, and they must have a explicit state to define the result's type. Because these types have different range and meaning.
Explain the philosophy behind this language decision
Rust avoids to create a mistake or unclear behavior, especially memory error (like range overflow).
1.3
Question
Your friend has asked you to teach them Rust. They think a great place to begin would be your teaching them to write their own implementation of a doubly-linked list (i.e. a list in which each node is stored on the heap, with references to the previous node and the next node).
Question:
Give two reasons to explain why this is not a problem well-suited for Rust. (1 mark per reason)
- It could break ownership and borring rules. In doubly-linked list, each node neeeds to have pointers to both sides' nodes. And it could occur multiple ownership and cyclic references.
- Adding node and deleting node should operate the pointers, and it could occur some dangling references or wild pointers. It is dangerous in Rust and developer should handle these under the security rules. It is cumbersome.
1.4
Question
A COMP6991 student has decided to build their own operating system in Rust. When implementing the ability to open and read from files, they design these functions based on how Linux deals with files.
RUST/// This function takes a path to a file; and a mutable reference to a `usize`.
/// If the file at `file_path` can be opened, the function will write a unique
/// `file_id` to the given mutable reference, and return 0. If the file cannot
/// be opened, the function will return an error code.
fn open_file(file_path: &str, file_id: &mut usize) -> usize;
/// This`function takes a `file_id` the user has already obtained, as well as a
/// `buffer` to write bytes to, and a `max_read_size`. The function tries to
/// copy `max_read_size` bytes into `buffer`. It returns the actual number of
/// bytes read. If there is an error, it returns a negative error code.
fn read_file(file_id: i32, buffer: &[u8], max_read_size: usize) -> i32;
Question:
Identify three issues in this students plan (either with their design, or their ability to implement their plan in Rust), and three accompanying Rust features that could be used to fix them. (1 mark per issue+fix)
- It should use
Result<T, E>to return result. This could make it easy to handle error and next step. - buffer should be mutable reference, because we should input some data in it.
usizedoes not have negative value, but error code could be negative. Therefore, these two functions should useResult<T, E>to solve that risk.
Question 2
Question
In this activity, you will be finding the differences between two rolls of people. A COMP6991 tutor has collected two rolls of people, and wants to know who's unique to the first one; who's unique to the second one; and who is on both lists.
You will be given two string references, called left and right. On each line is the name of a person. For every person on the left roll, you should return either DiffResult::LeftOnly or DiffResult::Both containing a string reference to that line, depending on whether they're in the right list also. For every person on the right roll, you should return DiffResult::RightOnly containing a reference to that line if they are not in the left roll. You can assume that the people on any single roll are unique. That is, you won't see two of the same person on the left roll, nor two of the same person on the right roll.
Before returning, you should sort your list of differences alphabetically by their names. Note that since DiffResult derives PartialOrd + Ord, you should simply be able to call .sort() on your final Vec.
You have been given starter code which does not yet compile. Your task is to fill in the todo!() statement, as well as to modify the lifetimes where required in order to build your code.
You are not permitted to change the return type of functions, the names of structs, or the types of structs. You may also not change the main function, and you should expect that the main function will be changed during testing. Specifically, the main function could be changed to extract DiffResult::RightOnly or DiffResult::Both. You will, however, have to add or modify lifetimes to existing types in order to successfully compile your code.
This is an example of the expected behaviour:
$ 6991 cargo run test_data/test_data.txt Finished dev [unoptimized + debuginfo] target(s) in 0.36s Running `target/debug/prac_q2` # Roll 1 Tom Shrey Zac Hailey Toby Barry Netanya # Roll 2 Tom Shrey Hailey Left Only: Barry Left Only: Netanya Left Only: Toby Left Only: Zac
RUST#[derive(Debug, PartialOrd, Ord, PartialEq, Eq)]
pub enum DiffResult<'a, 'b> {
LeftOnly(&'a str),
RightOnly(&'b str),
Both(&'a str)
}
pub fn compare_rolls<'a, 'b>(left_roll: &'a str, right_roll: &'b str) -> Vec<DiffResult<'a, 'b>> {
use std::collections::HashSet;
let left_names: HashSet<_> = left_roll.lines().collect();
let right_names: HashSet<_> = right_roll.lines().collect();
let mut result = Vec::new();
for &name in &left_names {
if right_names.contains(name) {
result.push(DiffResult::Both(name));
} else {
result.push(DiffResult::LeftOnly(name));
}
}
for &name in &right_names {
if !left_names.contains(name) {
result.push(DiffResult::RightOnly(name));
}
}
result.sort();
result
}
Question 3
Question
In this task, you will build a data-structure, called a "DBMap". This type will wrap a Vec of tuples, of the form (key, value). Currently, the type only works for tuples of the form (i32, &'static str), however you will need to modify this so it works for any tuples where the key is Eq. Your task is to make this struct generic over all valid types for both its keys and values, then to implement a method on this data-structure.
The method you will implement is called merge. It should take ownership of two DBMaps with the same type of key, and then return a new DBMap with its values being tuples. To describe the algorithm merge uses, we will call one of the DBMaps self, and one of them other.
To create the new DBMap, you should iterate over each element in self. We will call these key and value You should then try to find the first element in other with an equal key. We will call that other_value. You should insert (key, (value, Some(other_value))) into the new DBMap. If you cannot find a matching value in other, you should insert (key, (value, None)) into the new DBMap.
Your implementation should be generic, such that the key is any type which supports equality checking; and the value is any type.
Your implementation should compile with both the main functions provided, however you should assume that more main functions may be tested during marking.
You may assume that any one individual DBMap will be comprised of totally unique keys.
An example of a merge is shown below:
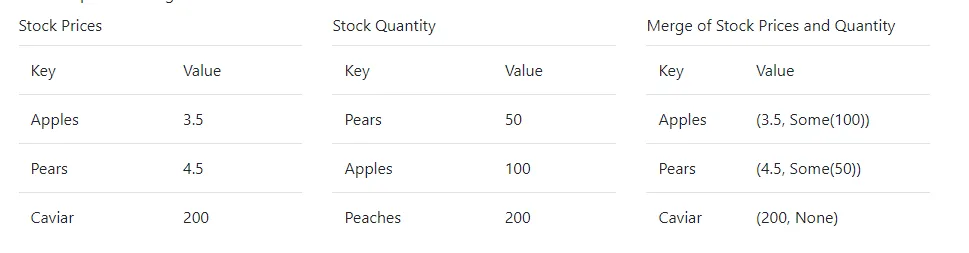
$ 6991 cargo run Finished dev [unoptimized + debuginfo] target(s) in 0.00s Running `target/debug/exam_q3` #1: Max Verstappen (Red Bull Racing) #3: Daniel Riccardo (None) #4: Lando Norris (McLaren) #5: Sebastian Vettel (None) #6: Nicholas Latifi (None) #7: Kimi Räikkönen (None) #9: Nikita Mazepin (None) #11: Sergio Pérez (Red Bull Racing)
Question 4
4.1
Question
Therese is writing a library to help sell her car. The library defines a Car trait as follows:
RUSTtrait Car {
fn get_price(&self) -> u32;
}
Users of the library will create their own structs which represent specific cars by implementing the Car trait. As seen in the trait definition, all Cars have a price.
Therese wants to write a function to total the cost of all the cars in a slice. As she wants this to work for any models of Car, she considers two potential approaches:
RUSTfn get_total_price<C: Car>(cars: &[C]) -> u32;
and
RUSTfn get_total_price(cars: &[Box<dyn Car>]) -> u32;
Question:
- Explain the difference between the two approaches. (1 mark)
- Give one reason why Therese might choose each approach. (1 mark)
Explain the difference between the two approaches.
Approach 1 use generic, so that it has to implement the Car trait and this function should give a specific verson for each kind of Car when it is compiling.
Approach 2 use dyn Car to have a dynamic reference to every type of Car trait. Every element in cars would be a pointer to a Car instance.
Give one reason why Therese might choose each approach.
Approach 1 usually have better performance because it has some optimizations in compiling time. In addition, the generic could avoid runtime handling of type information to save cost.
Approach 2 is more flexible because one function could be used in many kinds of Car instance types.
4.2
Question
Daniel is trying to design a function that counts the number of whitespace characters in some text. He starts with the first design...
RUSTfn number_of_whitespace_chars(string: String) -> usize {
string.chars()
.filter(char::is_whitespace)
.count()
}
... and submits this for code review. Another software engineer on his team suggests the following change...
RUSTfn number_of_whitespace_chars(string: &str) -> usize {
string.chars()
.filter(char::is_whitespace)
.count()
}
... which Daniel accepts and resubmits. Finally, a senior engineer suggests a further change:
RUSTfn number_of_whitespace_chars<T: AsRef<str>>(t: T) -> usize {
t.as_ref()
.chars()
.filter(char::is_whitespace)
.count()
}
Question:
- Why is the first suggested change an improvement on Daniel's original design? (1 mark)
- Why is the second suggested change an improvement on the second design? (1 mark)
Why is the first suggested change an improvement on Daniel's original design?
The first suggested change: &str is a reference pointer and it does not has data. This suggestion could avoid some ownership or borrowing problems, save memory and improve performance.
Why is the second suggested change an improvement on the second design?
The second suggested change: It makes this function more flexible. Now it could accept any type of string slice, including String, &str, Option and Result, etc. This funciton could support more context and need not change lots of codes.
4.3
Question
Olivia is working on a roll-call system to help take attendance at a class she teaches. She writes the following code:
RUSTtrait IntoRollCall {
fn into_roll_call(self) -> String;
}
struct UnswStudent {
name: String,
zid: u32,
}
impl IntoRollCall for UnswStudent {
fn into_roll_call(self) -> String {
let Self { name, zid } = self;
format!("{name} z{zid}")
}
}
fn call_roll(students: Vec<Box<dyn IntoRollCall>>) {
for student in students.into_iter() {
println!("{}", student.into_roll_call());
}
}
fn main() {
call_roll(vec![
Box::new(UnswStudent { name: String::from("Alice"), zid: 5000000 }),
Box::new(UnswStudent { name: String::from("Bertie"), zid: 5000001 }),
Box::new(UnswStudent { name: String::from("Candice"), zid: 5000002 }),
]);
}
Although there is currently only one implementor of IntoRollCall, she plans to soon add more implementors for other schools.
However, when she attempts to compile the code, she gets a confusing error:
$ rustc my_program.rs error[E0161]: cannot move a value of type `dyn IntoRollCall` --> my_program.rs:19:24 | 19 | println!("{}", student.into_roll_call()); | ^^^^^^^^^^^^^^^^^^^^^^^^ the size of `dyn IntoRollCall` cannot be statically determined error: aborting due to previous error For more information about this error, try `rustc --explain E0161`.
Question:
- Explain the reasoning behind this error message, with specific reference to the requirements of trait objects. (2 marks)
- Identify a simple solution to fix Olivia's program. (1 mark)
Explain the reasoning behind this error message, with specific reference to the requirements of trait objects.
When she uses a dynamically dispatched trait object dyn IntoRollCall, Rust could not know the size of it because different structures may have different sizes but be for the same trait. And in Rust, this size-unknown element could not move like into_roll call().
Identify a simple solution to fix Olivia's program.
Edit IntoRollCall trait and use &self reference to replace data self to avoid the ownership problem.
RUSTtrait IntoRollCall {
fn into_roll_call(&self) -> String;
}
impl IntoRollCall for UnswStudent {
fn into_roll_call(&self) -> String {
let Self { name, zid } = self;
format!("{name} z{zid}")
}
}
fn call_roll(students: Vec<Box<dyn IntoRollCall>>) {
for student in students.iter() {
println!("{}", student.into_roll_call());
}
}
4.4
Question
Patel does not think Rust's generics system is that special. He claims he can write his own macro which does everything that Rust's generics system can do.
His macro, and an example of him using it, is shown below.
RUSTmacro_rules! generic {
($($name:ident = $type:ty),+; fn $fn_name:ident($($arg_name:ident: $arg_type:ty),* ) -> $return_type:ty $blk:block) => {
$(type $name = $type);+;
fn $fn_name($($arg_name: $arg_type),*) -> $return_type {
$blk
}
}
}
generic!(I = i32, O = String; fn add(a: I, b: I) -> O {
format!("{}", a + b)
});
fn main() {
let a: i32 = 1;
let b: i32 = 1;
println!("{}", add(a, b));
}
Question:
- Explain to Patel three features of Rust's generics system which his macro does not implement, with explicit reference to an example of how his system would have to implement it. (1 mark per feature)
- Trait Bounds: Rust's generics system allows for trait bounds, which restrict the types that can be used with a generic function or struct. This is something that Patel's macro does not implement. For example, if we wanted to ensure that the types used with a function implement the
std::fmt::Displaytrait, we could do so with Rust's generics system like so:
rustfn display<T: std::fmt::Display>(item: T) {
println!("{}", item);
}
To implement this in Patel's macro system, he would need to add a way to specify trait bounds and then include those in the function definition.
- Multiple Types: Rust's generics system allows for functions and structs to be generic over multiple types. This is something that Patel's macro does implement, but it does so in a way that requires each type to be explicitly named. In contrast, Rust's generics system allows for an arbitrary number of types to be used. For example:
rustfn multi_generic<T, U>(t: T, u: U) {
// ...
}
To implement this in Patel's macro system, he would need to add a way to specify an arbitrary number of types without having to give each one a unique name.
- Lifetimes: Rust's generics system also includes support for lifetimes, which are a way of ensuring that references are valid for a certain scope of code. This is something that Patel's macro does not implement. For example, if we wanted to create a function that returns a reference to one of its arguments, we could do so with Rust's generics system like so:
rustfn choose_first<'a, T>(first: &'a T, _second: &T) -> &'a T {
first
}
To implement this in Patel's macro system, he would need to add a way to specify lifetimes and then include those in the function definition.
Question 5
5.1
Question
The following code attempts to creates multiple threads which each increment an i32 protected by a Mutex by one.
rustuse std::thread;
use std::sync::Mutex;
fn main() {
let mutex: Mutex<i32> = Mutex::new(0);
thread::scope(|scope| {
for _ in 0..3 {
let mut i = mutex.lock().unwrap();
scope.spawn(move || {
*i += 1;
});
}
});
println!("{}", *mutex.lock().unwrap());
}
However, there is a mistake in this code. Fortunately, it is caught by the Rust compiler instead of causing a crash or undefined behaviour at runtime.
Question:
- Explain how the Rust compiler knows (statically, at compile time) that i cannot be sent across threads. (1 mark)
- Explain how you would change the code to compile, while maintaining the behaviour that each thread increments the i32 by exactly one. (1 mark)
- Explain why your change fixes the issue. (1 mark)
Explain how the Rust compiler knows (statically, at compile time) that i cannot be sent across threads.
MutexGuard does not have Send trait, which allows types to be sent across threads, because it is related to Mutex lock and Rust should avoid dangling lock.
Explain how you would change the code to compile, while maintaining the behaviour that each thread increments the i32 by exactly one.
Developer should change the lock position from out of thread function to inside. In addition, he should use Arc to allow Mutex could be shared across threads safely.
Explain why your change fixes the issue.
Every thread could get a specific lock when it is using data, and would not effect other threads because the Mutex is independent for every thread.
5.2
Question
- Identify a type that should never be marked as Sync. (1 mark)
- Explain why that type should never be marked as Sync. (1 mark)
Cell<T>: It provides interior mutability, and Sync will allow multiple threads to share its reference. It could lead data race and potencial memory safety problems.
5.3
相关信息
Zain claims on the course forum that Rust makes concurrency impossible to get wrong.
However, the next post shows a student struggling with their concurrent code:
RUSTuse std::thread;
use std::sync::{Mutex, Arc};
fn main() {
let mutex: Arc<Mutex<Vec<i32>>> = Arc::new(Mutex::new(Vec::new()));
for _ in 0..3 {
let mutex_clone = mutex.clone();
thread::spawn(move || {
{
// Push 1 to the end of the vec...
let mut vector = mutex_clone.lock().unwrap();
vector.push(1);
}
{
// ... then increment that element by 1.
let mut vector = mutex_clone.lock().unwrap();
let index = vector.len() - 1;
vector[index] += 1;
}
});
}
// NOTE: this code makes it work better for some reason???
for _ in 0..2000 {}
println!("{:?}", *mutex.lock().unwrap());
}
Question:
- Explain two concurrency issues with the student's code. (1 mark per issue)
- Discuss to what extent you agree with Zain's claim. (1 mark)
Explain two concurrency issues with the student's code.
- Data Race Problem: Although he uses
Mutexto manage sharedVec<i32>, every thread has 2 lock-unlock code: Push1and increase the index. However, this could cause data race because some thread might push or increase between another thread's pushing or increasing. - Sync Problem: The main thread could not wait for every sub-thread's end. It has used for a wait:
for _ in 0..2000 {}, but a better solution is usejoin().
Discuss to what extent you agree with Zain's claim.
"Something is impossible" is impossible. Rust could check lots of risks and issues during compiling, however, it does not mean that every problem could be solved automatically. Developers should also manage the sync and mutex to protect data safety.
5.4
相关信息
Analyse two Rust features which the Rayon crate is able to take advantage of in order to provide static (i.e. compile-time) guarantees as to the safety of a parallel computation. Ensure to explain both the Rust feature, and how it allows Rayon to provide such guarantees. (1 mark per feature)
- Mut reference: When it uses
par_iter(), it checks this data and confirm that it does not be used as a mutable reference in this program so that it could avoid data race. - Lifetime: When it uses
scope(), the data must have a lifetime so taht it could avoid dangling pointer.
Question 6
Question
In this exercise, we will be making some mathematical operations occur in parallel. You have been given the code to calculate the factors of a number, and to find common factors between two numbers. This code is quite slow, as it only executes on a single thread.
Your task is to parallelise the code in your main function. You can use any concurrency tools within the standard library, but you must not use Rayon, or any other non-standard crates. You must not change any code outside the main.rs file.
You will receive full marks if you can ensure that (theoretically), all calls to get_factors could run simultaneously; and seperately that all calls to get_common_factors could run simultaneously.
You should not put a constant limit on the number of threads you spawn (i.e., do not use thread-pooling). We suggest that you spawn a new thread for each get_factors call, and a new thread for each get_common_factors call.
Question 7
Question
The following code attempts to write an (inefficient, but simple) implementation of a Mutex using unsafe.
RUSTuse std::{cell::UnsafeCell, sync::Mutex, ops::{Deref, DerefMut}};
pub struct MyMutex<T> {
data: UnsafeCell<T>,
is_locked: Mutex<bool>,
}
impl<T> MyMutex<T> {
pub fn new(data: T) -> Self {
Self {
data: UnsafeCell::new(data),
is_locked: Mutex::new(false),
}
}
pub fn lock<'lock>(&'lock self) -> MyGuard<'lock, T> {
loop {
let mut is_locked = self.is_locked.lock().unwrap();
if !*is_locked {
// we now hold the lock!
*is_locked = true;
return MyGuard { mutex: self };
}
}
}
}
// Safety: Mutexes are designed to be used on multiple threads,
// so we can send them to other threads
// and share them with other threads.
unsafe impl<T> Send for MyMutex<T> {}
unsafe impl<T> Sync for MyMutex<T> {}
pub struct MyGuard<'lock, T> {
mutex: &'lock MyMutex<T>,
}
impl<T> Deref for MyGuard<'_, T> {
type Target = T;
fn deref(&self) -> &Self::Target {
// Safety: We hold the lock until we are dropped,
// so we have exclusive access to the data.
// The shared borrow of the data is tracked through
// the shared borrow of self (elided lifetime).
unsafe { &*self.mutex.data.get() }
}
}
impl<T> DerefMut for MyGuard<'_, T> {
fn deref_mut(&mut self) -> &mut Self::Target {
// Safety: We hold the lock until we are dropped,
// so we have exclusive access to the data.
// The exclusive borrow of the data is tracked through
// the exclusive borrow of self (elided lifetime).
unsafe { &mut *self.mutex.data.get() }
}
}
impl<T> Drop for MyGuard<'_, T> {
fn drop(&mut self) {
*self.mutex.is_locked.lock().unwrap() = false;
}
}
It can be used like this, which produces the correct, expected output:
RUSTmod my_mutex;
fn main() {
use std::thread;
use my_mutex::MyMutex;
const N_THREADS: u64 = 20;
const N_INCREMENTS: u64 = 1000;
const EXPECTED: u64 = N_THREADS * N_INCREMENTS;
let my_mutex: MyMutex<u64> = MyMutex::new(0);
thread::scope(|scope| {
for _ in 0..N_THREADS {
scope.spawn(|| {
for _ in 0..N_INCREMENTS {
*my_mutex.lock() += 1;
}
});
}
});
let final_value = *my_mutex.lock();
println!("Final value: {final_value} (expected {EXPECTED})");
}
$ cargo run Finished dev [unoptimized + debuginfo] target(s) in 0.00s Running `target/debug/mutex_broken` Final value: 20000 (expected 20000)
Furthermore, running with Miri (eventually) produces nothing out of the ordinary:
$ cargo +nightly miri run Preparing a sysroot for Miri (target: x86_64-unknown-linux-gnu)... done Finished dev [unoptimized + debuginfo] target(s) in 0.00s Running `/home/zac/.rustup/toolchains/nightly-x86_64-unknown-linux-gnu/bin/cargo-miri runner target/miri/x86_64-unknown-linux-gnu/debug/mutex_broken` Final value: 20000 (expected 20000)
Note that if you plan to run the code with Miri yourself, you might want to consider decreasing the constants' values - Miri is particularly slow to run.
However, there exists a subtle unsoundness in MyMutex. In certain conditions, it is possible for an end-user of MyMutex to cause undefined behaviour without writing any unsafe. In particular, it is possible to cause a data race using only safe code.
NOTE:
Note that MyMutex uses a Mutex internally to store the lock_held state, however a more appropriate type here would have been an AtomicBool instead. A Mutex was specifically chosen to limit the scope of unsoundness, and its choice in place of an AtomicBool is not relevant to the unsoundness you are tasked to find.
Question:
- What is the soundness issue in MyMutex, and how could it be fixed? (3 marks)
- Provide a short example main function using only safe Rust that can reproduce a data race by exploiting the located unsoundness when run with Miri. (2 marks)
What is the soundness issue in MyMutex, and how could it be fixed?
MyMutex could not protect the data in a multiply thread environment. Although there is Mutex to lock a boolean, that boolean could be locked for threads without unlock progress.
It should use some Atom, or make some time delay to ensure that the lock has been released completely.
Provide a short example main function using only safe Rust that can reproduce a data race by exploiting the located unsoundness when run with Miri.
RUSTuse std::thread;
use std::sync::Arc;
use my_mutex::MyMutex;
fn main() {
let counter = Arc::new(MyMutex::new(0));
let handles: Vec<_> = (0..2).map(|_| {
let counter = Arc::clone(&counter);
thread::spawn(move || {
for _ in 0..1000 {
// Lock the mutex and read the value
let guard = counter.lock();
let val = *guard;
// Explicitly drop the guard
std::mem::drop(guard);
// Here we introduce a very short sleep to increase the chance of a race condition
thread::yield_now();
// Another lock to increment the value
*counter.lock() = val + 1;
}
})
}).collect();
for handle in handles {
handle.join().unwrap();
}
println!("Final value: {}", *counter.lock());
}
Question 8
Question
The final question of the exam will be a more open-ended question which will ask you to perform some analysis or make an argument. Your argument will be judged alike an essay (i.e. are your claims substantiated by compelling arguments). Remember that you will not get any marks for blindly supporting / opposing Rust.
A friend of yours has just read an article critical of Rust, written approximately 7 years ago. Following is a relevant excerpt of the article for you to read. The original article is a very long and challenging read, so please only read / consider this excerpt.
# Criticizing the Rust Language, and Why C/C++ Will Never Die Eax Melanhovich, May 12 2015. I believe Rust is overhyped, and that the death of C and C++ are over-exaggerated. It is crystal clear for every sane programmer that C/C++ is not going to die in the near future. No one is going to rewrite almost all of the existing desktop applications, operating system kernels, browser engines, tons of other C-libraries, and so on and so forth, into other languages. This is a huge mass of fast, debugged, and time-proven code. Rewriting it is way, way too expensive, risky, and, honestly, doesn't seem to make sense except in the heads of the most frantic Rust fans. The demand for C/C++ programmers has always been high and will remain so for a long time to come. C/C++ is criticized for a variety of reasons. Briefly, the issue with C++ is that it is very fast but it is not safe in the sense that it allows array overruns, addressing freed memory, and so on. Back in the past, this problem urged programmers to develop a variety of safe languages such as Java, C#, Python, and others. But they have proved to be too resource-demanding compared to C++. That's why programmers are struggling to create a language as fast as C++ but also safe. Rust is one of the candidates. And what actually makes Rust safe, by the way? To put it simple, this is a language with a built-in code analyzer, and it's a pretty tough one: it can catch all the bugs typical of C++, dealing not only with memory management, but multithreading as well. Pass a reference to an assignable object through a pipe to another thread and then try to use this reference yourself - the program will just refuse to compile. And that's really cool. But other languages haven't stood still during the last 30 years, and there are many compile-time and runtime analysers which will check your code for issues. In any serious project, you use a continuous integration system and run tons of tests when compiling builds. If you don't, then your troubles are much worse than the language's lack of safety because static typing doesn't guarantee correct execution logic! So, since you run tests anyway, why not use sanitizers as well? True, they don't find all the bugs. But it's still pretty good, and you don't need to deal with performance issues caused by checking the bounds of an array at runtime, or the pain that the Rust compiler forces you into. Even without sanitizers, you'll find lots of stuff just building the project with various compilers on different platforms with assert's checking your code's invariants in the "assert(obj->isValid)" fashion and with proper fuzzing. Even apart from that, I'm also skeptical about the language's design as such. In particular with regards to the many types of pointers used in it. On the one hand, it's not bad to make programmers ponder if their variables are stored in the stack or heap and if they can or cannot be handled by several threads at a time. But on the other hand, imagine you are writing a program and discover at one moment that some variable should be stored in the heap instead of the stack. So you rewrite the code to use Box. Then you figure out that you actually need Rc or Arc. Again, you rewrite all that code. And then, once again, you rewrite it all to have an ordinary variable in the stack. Regular expressions won't help. Or you might just end up with a nightmare like "Vec<Rc<RefCell<Box<Trait>>>>" - say hello to Java! It would be much more convenient to let the programmer simply declare a variable and explicitly specify Box or Rc where necessary. From this viewpoint, Rust's developers have screwed up the whole thing. Like many of new languages, Rust is walking the path of simplification. I can generally understand why it doesn't have inheritance and exceptions, but the fact itself that someone is making decisions for me regarding things like that makes me feel somewhat displeased. C++ doesn't restrict programmers regarding what they can or cannot use. I can't help but remind you one more time that the source of troubles is usually in humans, not technology. If your C++ code is not good enough or Java code is painfully slow, it's not because the technology is bad - it's because you haven't learned how to use it right. In that sense, you won't be satisfied with Rust either - but just for some other reasons. Isn't it easier to learn how to use more popular tools and start liking them? So, to sum it up, personally I will be investing my time into studying C/C++ rather than Rust in the next 5 or so years. C++ is an industrial standard. Programmers have been using it to solve a huge variety of tasks for over 30 years now. As for Rust and stuff like that - they are just odd toys with a vague future. People have been predicting C++'s soon death since the 2000-s, but C/C++ haven't become less used and demanded for since then.
From https://pvs-studio.com/en/blog/posts/0324/.
Read through the excerpt, and discuss the following prompt:
Rust is too strict and too painful to be useful, as explained by this article.
The overall structure of your answer is not marked. For example, your answer may include small paragraphs of prose accompanied by dot-points, or could instead be posed as a verbal discussion with your friend. Regardless of the structure / formatting you choose, the substance of what you write is the most important factor, and is what will determine your overall mark for this question.
Only responses less than 1000 words will be marked for this question. There will be many good answers that are significantly shorter (see above), this limit is a cap to save our marking time, and your sanity.
本文作者:Jeff Wu
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!